基本信息
论坛名称:大模型时代的图象图形技术变革与实践
论坛介绍
由AI大模型引领的创新浪潮席卷全球,掀起产业升级的蝶变。作为人工智能领域一项基础性、普适性技术,图象图形技术如何乘大模型之风,实现技术突破、抓住发展新契机,是学术界和产业界共同热议的话题,更是亟待解决的问题。
本论坛汇集百度AI专家、知名高校学者,共同探讨大模型时代的图象图形技术变革与实践,多维度分享如何运用AI大模型应对图象图形技术挑战以及视觉大模型应用落地的实战经验,内容涵盖计算机视觉领域的核心基础问题、经典的智能文档图像识别和理解任务、热门的AIGC技术探索与进展等等,希望为与会学者提供开源开放的交流平台。
论坛主席

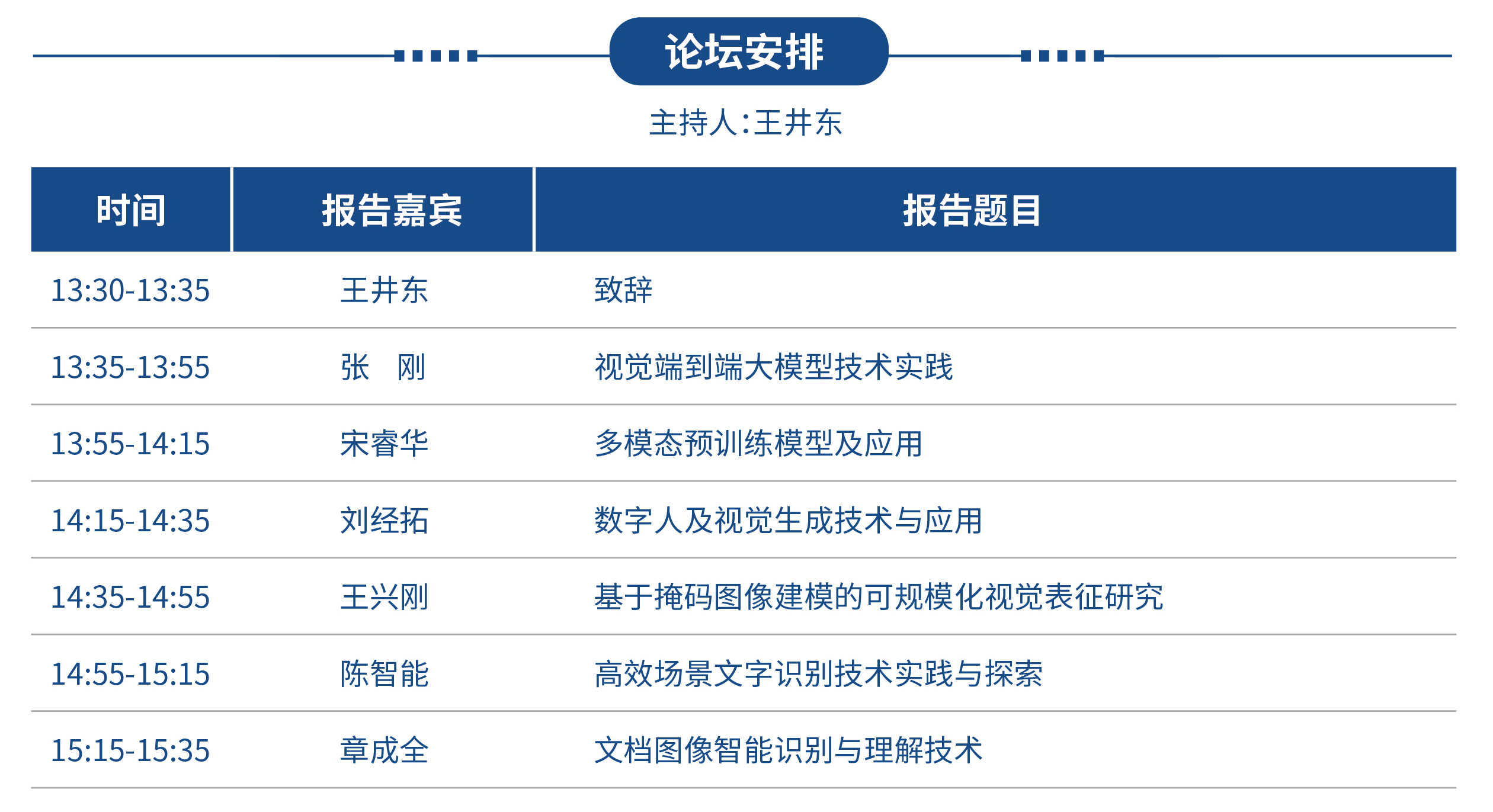
姓名:王井东
单位和职称:百度计算机视觉首席科学家
个人简介:王井东,百度计算机视觉首席科学家。加入百度之前,曾任微软亚洲研究院视觉计算组首席研究员。研究领域为计算机视觉、深度学习及多媒体搜索。他的代表工作包括高分辨率神经网络(HRNet)、基于transformer attention的图像语义分割网络OCRNet、以及基于近邻图的大规模最近邻搜索(NGS,SPTAG)等。他曾担任过许多人工智能会议的领域主席,如 NerIPS、CVPR、ICCV、ECCV、AAAI、IJCAI、ACM MM等。他现在是IEEE TPAMI和IJCV的编委会成员。他是IEEE/IAPR Fellow、ACM Distinguished Member。
报告嘉宾

姓名:张刚
单位和职称:百度视觉技术部
报告题目:视觉端到端大模型技术实践
个人简介:张刚,硕士毕业于西安电子科技大学,百度人脸识别团队技术负责人,研究方向包含人脸识别、开放域数据挖掘、视觉多任务大模型和模型小型化等技术。主导研发170亿参数视觉多任务大模型文心VIMER-UFO 2.0,孵化PaddleSlim开源模型压缩工具,并将相关技术应用到百度数十个重要产品线。在CVPR、ICCV、ECCV等视觉顶会上发表多篇论文,曾带队获得多项国际权威竞赛冠军。连续三年组织CVPR NAS workshop,在CVPR 2023上组织第一届Foundation Model Workshop和视觉大模型竞赛。

姓名:宋睿华
单位和职称:中国人民大学高瓴人工智能学院
报告题目:多模态预训练模型及应用
个人简介:宋睿华博士,中国人民大学高瓴人工智能学院长聘副教授,国家高层次人才专家,曾任微软亚洲研究院主管研究员和微软小冰首席科学家。她的算法完成了人类史上第一本人工智能创作的诗集《阳光失了玻璃窗》。她也是文澜多模态预训练项目的学术带头人,已发布6.5亿图文数据上预训练的文澜2.0和1千万视频文本数据上预训练的文澜3.0,并成功落地多个产品(如OPPO手机中的为视障人士读图功能)。宋睿华博士是具有国际影响力的人工智能科学家,发表学术论文90余篇,申请国际专利25项。最近的研究兴趣包括多模态理解、创作和交互。她是SIGIR 2023讲习班的主席、ACL和SIGIR的Area Chair和Senior PC,还是Information Retrieval Journal的主编。

姓名:刘经拓
单位和职称:百度视觉技术部
报告题目:数字人及视觉生成技术与应用
个人简介:刘经拓,硕士毕业于清华大学,有超过10年的计算机视觉算法研究与落地经验。研发了国内首个全网人脸搜索引擎,在人脸、OCR、NAS等领域发表多篇CVPR、ECCV等顶会学术论文,并获得过Widerface、VOT多项学术竞赛冠军,主导研发的人脸识别技术入选2017年”MIT世界十大技术突破”之一。目前担任百度视觉技术部杰出架构师,负责百度数字人技术和增强现实技术的研发工作。

姓名:王兴刚
单位和职称:华中科技大学电信学院
报告题目:基于掩码图像建模的可规模化视觉表征研究
个人简介:王兴刚,华中科技大学电信学院教授、博士生导师,入选国家青年人才计划,Elsevier Image and Vision Computing期刊共同主编。主要研究方向为视觉目标检测与分割,在IEEE TPAMI、IJCV、CVPR、ICML等顶级期刊会议发表学术论文50余篇,谷歌学术引用次数1.7万余次,其中CCNet方法在AlphaFold中作为骨干网络被使用,ByteTrack方法在ECCV 2022最具影响力论文中排名第一。担任CVPR 2022、ICCV 2023、ICIG 2023领域主席,Pattern Recognition等期刊编委。入选了中国科协青年人才托举工程,获CSIG青年科学家奖,CAAI吴文俊人工智能优秀青年奖,CVMJ 2021最佳论文奖,湖北省自然科学二等奖,华中科技大学青年五四奖章等,指导学生获2022年全国“互联网+”大赛金奖。

姓名:陈智能
单位和职称:复旦大学计算机科学技术学院,青年研究员,博士生导师
报告题目:高效场景文字识别技术实践与探索
个人简介:陈智能,中科院计算所博士,香港城市大学博士后,现为复旦大学计算机科学技术学院青年研究员,中国图象图形学学会多媒体专委会委员、副秘书长,主要研究方向为多媒体分析、计算机视觉、医学影像分析,主持了国家重点研发计划课题,多项国家自然科学基金项目,以及百度、腾讯、交通部公路院、软控等企事业单位的横向科研项目,在领域内知名学术期刊和会议上发表学术论文60余篇,担任多个知名国际会议的领域主席、高级程序委员等,以及多个知名国际期刊的审稿人。

姓名:章成全
单位和职称:百度视觉技术部
报告题目:文档图像智能识别与理解技术
个人简介:章成全,现任百度视觉技术部资深工程师,是百度文字识别算法负责人,支持百度云OCR引擎、百度视觉搜索、百度网盘智能文档等关键AI产品建设。于2016年在华中科技大学电子信息与通信学院获得硕士学位,毕业后加入百度视觉团队,专注于OCR检测和识别、文档智能理解、文本图像编辑等技术方向的研发工作。在文档领域相关国际会议和期刊上累计发表论文20多篇,获得ICDAR-RRC、VOT、中国人工智能多媒体信息识别技术竞赛等多项赛事冠军,并取得第23届国家专利银奖1项。
论坛日程
5月12日 下午